Online Video Object Segmentation via Convolutional Trident Network
Overview
Segmentation results

Abstract
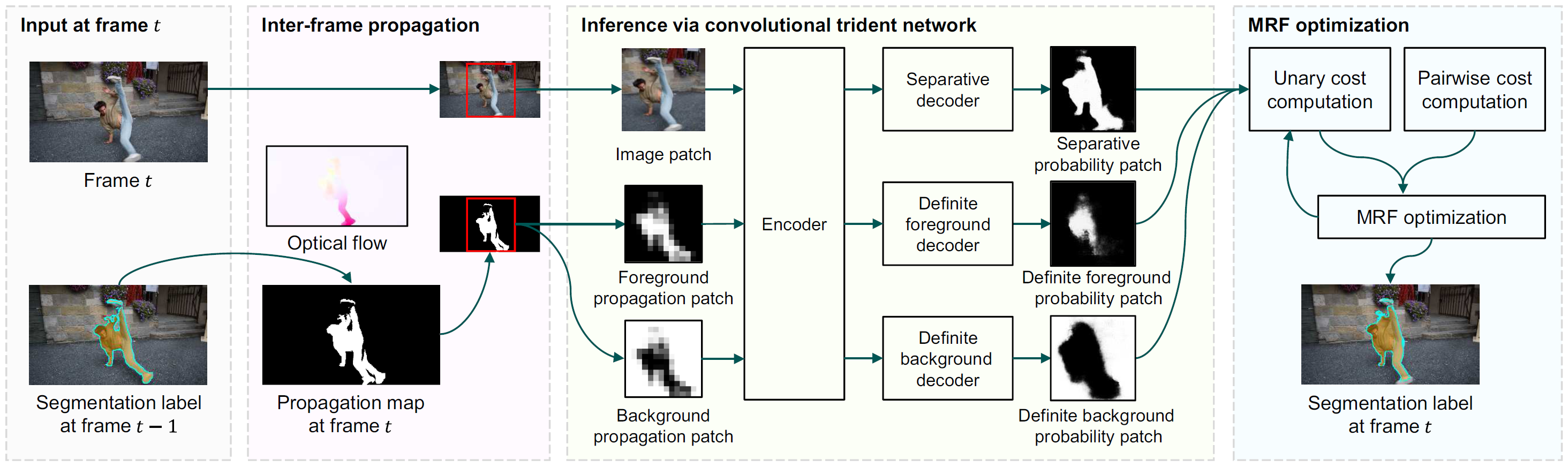
A semi-supervised online video object segmentation algorithm, which accepts user annotations about a target object at the first frame, is proposed in this work. We propagate the segmentation labels at the previous frame to the current frame using optical flow vectors. However, the propagation is error-prone. Therefore, we develop the convolutional trident network (CTN), which has three decoding branches: separative, definite foreground, and definite background decoders. Then, we perform Markov random field optimization based on outputs of the three decoders. We sequentially carry out these processes from the second to the last frames to extract a segment track of the target object. Experimental results demonstrate that the proposed algorithm significantly outperforms the state-of-the-art conventional algorithms on the DAVIS benchmark dataset.
Publication
Won-Dong Jang and Chang-Su Kim, "Online Video Object Segmentation via Convolutional Trident Network," in Proc. IEEE International Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, pp. 5849-5858, Jul. 2017. [pdf] [supplementary video]
Download
Source code: 2017_CVPR_WDJANG_CTN.tar.gz
Results on the DAVIS dataset: 2017_CVPR_WDJANG_CTN_DAVIS.zip