Continuously Masked Transformer for Image Inpainting
Abstract
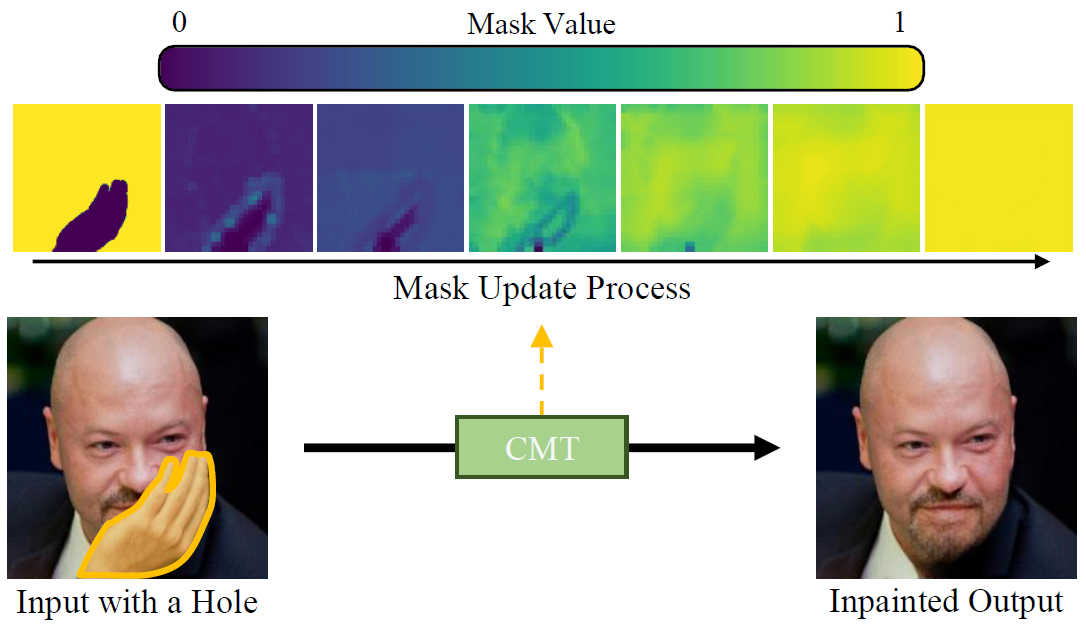
A novel continuous-mask-aware transformer for image inpainting, called CMT, is proposed in this paper, which uses a continuous mask to represent the amounts of errors in tokens. First, we initialize a mask and use it during the self-attention. To facilitate the masked self-attention, we also introduce the notion of overlapping tokens. Second, we update the mask by modeling the error propagation dur- ing the masked self-attention. Through several masked self- attention and mask update (MSAU) layers, we predict initial inpainting results. Finally, we refine the initial results to re- construct a more faithful image. Experimental results on multiple datasets show that the proposed CMT algorithm outperforms existing algorithms significantly. The source codes are available at https://github.com/keunsoo-ko/CMT.
Overview
Demo video
Publication
Keunsoo Ko and Chang-Su Kim,
"Continuously Masked Transformer for Image Inpainting," accepted to Proceedings of International Conference on Computer Vision (ICCV), 2023.
[paper] [supp] [code]